_For%20light%20backgrounds.svg)
.webp)



























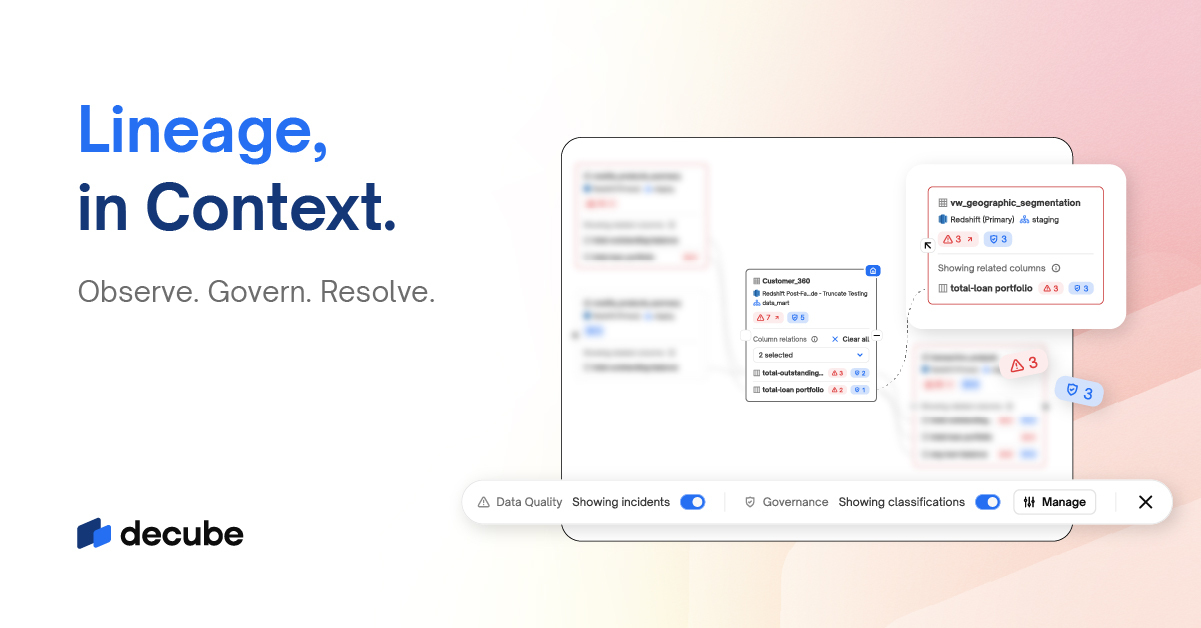
May Update: Faster Incident Response and Audit-Ready Lineage Exports
Our May Quality-of-Life updates focus on removing daily operational friction for data governance and compliance teams. In this update, we break down how our newly embedded incident lineage components, automated Snowflake metadata synchronization, and exportable data flows protect Data Trust while accelerating incident resolution.